
For anyone with an internet connection and a glut of time available for research, competitive data points are nearly inexhaustible. New job postings, minor website copy changes, new marketing content offers - daily movements in the market are endless. On their own, many of these individual data points are closer to worthless noise rather than signals of meaningful competitor movement. However, some can be incredibly valuable hints at shifts in competitor strategy.
How can you tell the difference?
While a single data point often fails to provide value, a series of data points that prove a hypothesis can help you predict the future. Predictive intelligence is one of the most valuable outputs of competitive intelligence (CI) efforts. Uncovering and quickly responding to competitor moves, while important, will never be as valuable as catching wind of those moves before they happen.
To corroborate a single data point, and confirm the existence of a broader trend, look to the past, present, and future to tell a story before it unfolds.
The Past
Major shifts in your competitors’ strategies are often planned and executed over an extended period of time. This is both good and bad news for CI pros. While longer periods of time give you more opportunities to uncover signs of a competitive shift, it also makes it difficult to immediately draw lines of significance between two related signals that surface months apart.

If you’re the type of CI pro who fastidiously captures, centralizes, and catalogs competitive data points on an ongoing basis, this isn’t an issue.
If that isn’t the case, remember the ancient adage: “The best time to establish a queryable CI database was 20 years ago. The second best time is today.”
Whether you leverage a dedicated CI platform or a series of complex spreadsheets, any single source of truth for competitive data needs to possess certain qualities to be useful in turning breadcrumbs into key insights. Cataloging data points by competitor, date, “type” of data point (messaging, product, hiring, etc.), and other similar filterable attributes is the first step. Tagging data with keywords more specific to the data point is even better. Let’s look at an example.
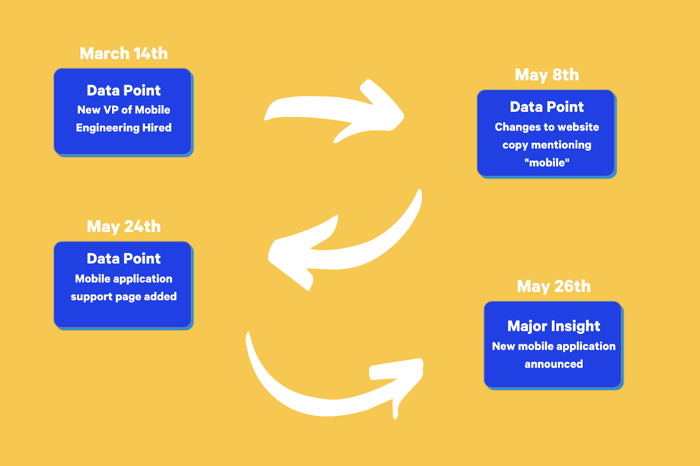
In the above hypothetical example, there are several key signals that surface well before a major competitive event unfolds. On March 14th, you wouldn’t be able to definitively predict that your competitor is developing a mobile application. Each data point collected in the graphic above should, at the very least, be tagged with the term “mobile”. Properly cataloging that data point, however, means that on May 8th, that individual signal becomes part of a story, and a hypothesis that a mobile app is in the works is closer to a solid prediction.
The Present
Sometimes your database of competitive data points doesn’t yield enough related signals to confirm a hypothesis. Sometimes a weak signal is all you have, but the potential implication of that signal is significant. An obvious step would be to frantically search for additional breadcrumbs across the vast expanse of the internet. While that is often a good idea, make sure to remember another key source of corroboration: tribal knowledge.
In an ideal world, any time someone in your organization learns even a small tidbit of information about a competitor, they would sound the alarm and socialize that finding. Reality is rarely so kind to CI pros. For that reason, proactively seeking out any further data points that support or refute your hypothesis amongst your peers is not a bad idea. Setting up a Slack or similar instant messaging channel related to competitive intel provides a perfect setting to ask if anyone has heard anything about Competitor X developing a mobile application.
For a more scalable process, treat field intel and tribal knowledge similar to all other data points. Whenever colleagues socialize competitive data points, log them in whatever repository you use as your single source of truth for CI. And, much like other data points, categorize and tag each data point. This is how you can avoid important competitive intel living solely in peoples’ heads and create a more unified source of competitive knowledge.
The Future
If your database of past findings and research externally and internally fails you, ongoing competitor monitoring is your last line of defense. In this case and in many others, ad-hoc competitive research is the enemy. It’s critical that you are able to detect and surface any related signals as quickly as they arise. In many cases, the early signal (or signals) you receive about a major competitor move are often not corroborated until a few weeks or days before the fact. The faster you can surface and act on new information, the better.
Make sure to dedicate at least a small amount of time to competitor monitoring every day. If you organize your process correctly, you can find a meaningful amount of information without sinking a significant amount of time into the process. Lastly, be sure you have an action plan in place once you uncover and corroborate information. Quickly uncovering key intel is worthless if your organization moves too slowly in its response.
Weak competitive signals can become advanced indicators of major competitor movements. Predictive intelligence is a significant competitive advantage, so make sure to grab your Sherlock Holmes hat, make your CI database queryable, and start piecing together the competitive puzzle pieces.


Seeing is believing! Check out Crayon for yourself.

Related Blog Posts



Popular Posts
-
 Sales Battlecards 101: How to Help Your Sellers Leave the Competition In the Dust
Sales Battlecards 101: How to Help Your Sellers Leave the Competition In the Dust
-
 How to Create a Competitive Matrix (Step-by-Step Guide With Examples + Free Templates)
How to Create a Competitive Matrix (Step-by-Step Guide With Examples + Free Templates)
-
 The 8 Free Market Research Tools and Resources You Need to Know
The 8 Free Market Research Tools and Resources You Need to Know
-
 6 Competitive Advantage Examples From the Real World
6 Competitive Advantage Examples From the Real World
-
 6 Exceptional Brand Messaging Examples We Can All Learn From
6 Exceptional Brand Messaging Examples We Can All Learn From